
Qu’est-ce que la génération augmentée de récupération ?
La génération augmentée de récupération* est le processus consistant à optimiser le résultat d’un grand modèle de langage. Elle fait donc appel à une base de connaissances fiable, externe aux sources de données utilisées, pour l’entraîner avant de générer une réponse.
C’est ici que l’on introduit ses propres données liées à son domaine d’expertise.
*(RAG en anglais, GAR en français)
Les grands modèles de langage (LLM) sont entraînés avec d’importants volumes de données. Ils utilisent des milliards de paramètres pour générer des résultats originaux pour des tâches telles que répondre à des questions, traduire des langues et compléter des phrases. La génération augmentée de récupération étend les capacités déjà très puissantes des LLM à des domaines spécifiques ou à la base de connaissances interne d’une organisation. Le tout, sans qu’il soit nécessaire de réentraîner le modèle. Il s’agit d’une approche économique pour améliorer les résultats du LLM et qu’ils restent cohérents, précis et utiles dans de nombreux contextes.
Pourquoi la génération augmentée de récupération est-elle importante ?
Les LLM sont une technologie clé d’intelligence artificielle (IA). Ils alimentent les chatbots intelligents et d’autres applications de traitement du langage naturel. L’objectif est de créer des robots capables de répondre aux questions des utilisateurs dans divers contextes en croisant des sources de connaissances faisant autorité. Malheureusement, la nature de la technologie LLM introduit une imprévisibilité dans les réponses LLM. De plus, les données de formation LLM sont statiques et introduisent une date limite sur les connaissances dont elles disposent.
Les défis connus des LLM incluent :
- Présenter de fausses informations alors qu’il n’y a pas de réponse.
- Présenter des informations obsolètes ou génériques lorsque l’utilisateur attend une réponse spécifique et actuelle.
- Créer une réponse à partir de sources ne faisant pas autorité.
- Créer des réponses inexactes en raison d’une confusion terminologique, dans laquelle différentes sources de formation utilisent la même terminologie pour parler de choses différentes.
Vous pouvez considérer le modèle linguistique large comme un nouvel employé trop enthousiaste qui refuse de se tenir informé de l’actualité, mais qui répondra toujours à toutes les questions avec une confiance absolue. Malheureusement, une telle attitude peut avoir un impact négatif sur la confiance des utilisateurs. Et ce n’est pas quelque chose que vous voulez que vos chatbots imitent !
La génération augmentée de récupération est une approche qui permet de résoudre certains de ces défis. Elle redirige le LLM pour récupérer des informations pertinentes à partir de sources de connaissances prédéterminées faisant autorité. Les organisations ont un meilleur contrôle sur la sortie de texte généré. Et les utilisateurs ont un aperçu de la manière dont le LLM génère la réponse.
Points à retenir
- Les modèles de RAG créent des référentiels de connaissances basés sur les données appartenant à l’entreprise. Les référentiels peuvent être continuellement mis à jour pour aider l’IA générative à fournir des réponses contextuelles et opportunes.
- La RAG est une technique d’intelligence artificielle relativement nouvelle. Elle peut améliorer la qualité de l’IA générative en permettant aux grands modèles de langage (LLM) d’exploiter des ressources de données supplémentaires sans réentraînement.
- Les chatbots et autres systèmes conversationnels qui utilisent le traitement du langage naturel peuvent grandement bénéficier de la RAG et de l’IA générative.
- La mise en œuvre de la RAG nécessite des technologies telles que des bases de données vectorielles. Elles vont permettre le codage rapide de nouvelles données, et des recherches sur ces données pour alimenter le LLM.
Comment avoir ma génération augmentée de récupération ?
Comment puis-je avoir ma propre IA qui répond à des questions dans mon domaine d’expertise et qui garantit la protection de mes données ?
Vous voudriez expérimenter la possibilité d’avoir votre propre RAG.
Je vais vous montrer une méthode simple d’y parvenir dans une environnement linux (debian) (https://github.com/imartinez/privateGPT).
Cette solution n’a pas vocation à être utilisée en production. Elle est simplement là pour vous montrer ce que pourrait vous apporter une RAG.
Il vous faudra exécuter les instructions suivantes :
git clone https://github.com/imartinez/privateGPT
cd privateGPT/
sudo apt-get install libgl1-mesa-glx libegl1-mesa libxrandr2 libxrandr2 libxss1 libxcursor1 libxcomposite1 libasound2 libxi6 libxtst6
curl -O https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh
chmod ./Anaconda3-2023.09-0-Linux-x86_64.sh
./Anaconda3-2023.09-0-Linux-x86_64.sh
conda create -n privategpt python=3.11
conda activate privategpt
conda install poetry
conda update keyring
sudo apt-get install build-essential
poetry install --with ui,local
poetry run python scripts/setup
pip install llama-cpp-python
PGPT_PROFILES=local make run
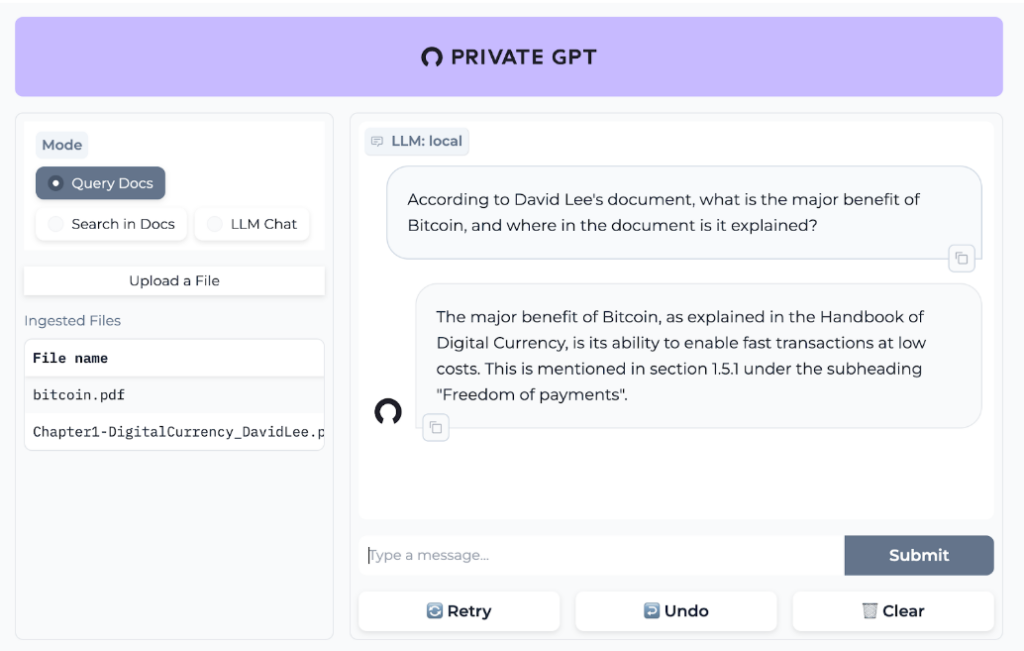
Désormais vous avez la possibilité de charger des fichiers pdf contenant vos informations.
Retrouvez nos articles sur notre série consacrée à l’IA (intelligence artificielle) :
Qu’attendre de l’IA pour la DSI en 2024 ?
Atlassian Intelligence, les fonctionnalités